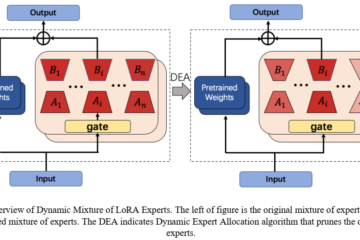
数据空间研究中心在大语言模型在法律领域应用方面取得了重大研究进展。
近日,数据空间研究中心在法律大模型研究领域发布了一项重要的研究成果,该成果围绕一种基于知识图谱增强的法律大语言模型展开,专门用于解决中国法律咨询中的复杂问题。
随着近年来人工智能技术的迅速发展,法律人工智能成为法律领域的研究热点之一。智能法律系统不仅能够为法律从业人员减轻繁重的文书工作,还能为公众提供方便、快捷的法律服务,包括远程咨询、自动法律文档生成等应用。然而,尽管人工智能在多个行业取得了显著进展,但在法律领域的应用仍面临严峻的挑战:法律问题往往复杂多变,涉及大量的专业知识和推理能力,现有的大语言模型在处理专业法律问题时,仍存在诸多局限。为了应对这些挑战,石镌铭同学自2024年起,联合中国电子科技集团公司电子科学研究院等多方科研力量,开展了关于法律大语言模型的研究工作。经过一年多的共同努力,研究成果以论文形式发表于国际会议《International Conference on Intelligent Computing》,论文题目为“Legal-LM: Knowledge Graph Enhanced Large Language Models for Law Consulting”。
研究背景及挑战
现有的大语言模型主要训练于通用数据集,虽然在跨领域适应性上表现优越,但其在法律领域的应用面临以下三大挑战:
1.知识不足:法律领域高度专业化,涉及大量的法律条文、判例、司法解释等复杂知识,而通用的大语言模型缺乏这些专业知识,导致在回答法律问题时,往往提供泛泛而谈的、不够专业的回答。
2.错觉问题:由于现有大语言模型依赖于大量非结构化数据进行训练,它们容易在推理时生成不准确甚至虚假的信息,特别是在面临高要求的法律推理任务时,现有模型缺乏足够的外部知识检索和验证能力,导致回答的可靠性不足。
3.非专业用户咨询的困难:普通用户在进行法律咨询时,往往使用非专业的语言,问题表达不够精确,这导致模型在理解和生成法律建议时出现偏差,从而难以提供有针对性的解答。
为了应对这些问题,Legal-LM提出了一系列创新性的方法和技术架构。

研究创新点
Legal-LM结合知识图谱、强化学习和大规模法律语料库,提出了一种全新的法律大语言模型架构,旨在提升模型的法律知识处理能力和用户法律咨询的回答质量。主要的创新点包括:

1. 基于法律知识图谱的预训练方法
Legal-LM在预训练阶段,首先从大量的法律条文、司法解释和案例中收集数据。这些数据最初是噪声较高、知识密度较低的非结构化文本。为了提高模型对法律知识的学习效果,研究团队通过数据清洗技术剔除噪声,并引入了结构化的法律知识图谱。知识图谱的引入将法律知识进行了系统的结构化,增强了模型对法律问题的理解和推理能力。
在预训练阶段,模型结合了知识图谱的数据,这不仅帮助模型掌握了大量的法律背景知识,还大幅提升了其对复杂法律任务的应对能力。通过预训练,模型能够从法律条款、司法解释中提取有效信息,避免了仅依赖于表面法律描述的现象,使得模型在处理实际法律咨询时能够更加精准地做出回应。
2. 关键词提取与DPO技术
为了应对非专业用户提出的模糊问题,Legal-LM采用了关键词提取技术,从用户的提问中提取出核心法律问题。该方法能够帮助模型更精准地理解用户的问题,并减少因非专业表达导致的解答误差。研究团队开发了一套专门的关键词提取算法,结合GPT接口,对用户的非专业提问进行优化处理,以确保模型能够准确抓住问题核心。
此外,Legal-LM还引入了DPO技术。DPO是一种强化学习方法,旨在通过优化用户的偏好来增强模型的输出效果。通过DPO,Legal-LM能够动态调整生成的法律建议,提供更加贴合用户需求的多样化答案。例如,在法律咨询场景中,DPO技术可以根据用户的不同偏好生成多种不同的建议,并优先选择最符合用户期望的答案。这样不仅提高了模型生成的准确性,还显著提升了用户的体验。
3. 外部法律知识库的引入与soft prompt技术
为了避免数据错觉问题,Legal-LM在回答用户问题时,结合了一个外部的法律知识库。该知识库涵盖了中国法律的多个类别,包括宪法、刑法、民法和专利法等。通过引入信息检索模块,模型可以在回答问题时自动匹配与用户提问相关的法律条文,从而确保生成的答案具有法律依据,减少错误信息的生成几率。
此外,Legal-LM还采用了soft prompt技术,在模型回答问题的过程中,外部知识库的内容会以软提示的形式嵌入到模型的输入中,帮助模型更好地理解用户的提问背景并提供更精确的答案。软提示技术极大地减少了大模型生成答案时因数据不准确带来的“幻觉”,提升了答案的可信度。
实验与评估
为了验证Legal-LM的有效性,研究团队在多个实验数据集上进行了广泛测试。实验结果表明,Legal-LM在法律问答、案件分析及法律建议生成等方面表现优异,显著优于现有的法律大语言模型。
在法律基础知识问答、全国统一法律职业资格考试题库等多个中国法律领域的测试集上,Legal-LM的表现明显优于其他模型。具体来说,Legal-LM在法律问题的回答准确率、问题理解的深度以及回答的完整性等方面均领先于其他模型。例如,在最具挑战的NJE数据集上,Legal-LM的回答准确率比现有的其他法律大模型高出超过10%。
| Model | LBK | UNGEE | NJE |
| Ziya-LlaMA-13B | 43.27 | 40.94 | 25.70 |
| ChatGLM-6B | 42.91 | 39.69 | 31.66 |
| Baichuan-13B-Chat | 53.45 | 50.00 | 31.47 |
| Legal-LM | 62.12 | 59.11 | 55.09 |
此外,研究团队还使用1000个来自实际法律咨询场景的主观法律问题,评估了Legal-LM在法律建议生成中的表现。评估指标包括准确性、完整性、清晰度和语言质量等维度,结果显示Legal-LM在这些指标上均表现优异,尤其是在答案的完整性和语言的清晰度上,领先于其他对比模型。

研究总结与展望
Legal-LM的成功开发标志着法律大模型领域的一次重要突破。通过结合知识图谱、强化学习和软提示技术,Legal-LM克服了传统大语言模型在法律咨询领域的局限,提供了更加准确、可靠和个性化的法律建议。这一研究成果不仅对法律人工智能的发展具有重要意义,还为中国法律服务的智能化提供了坚实的技术基础。
随着未来技术的进一步发展,Legal-LM有望在法律信息服务、法律教育和法律咨询等多个领域发挥更大作用,加速推动法律服务的数字化转型和智能化发展。这一创新研究不仅在学术界具有重要价值,也在法律服务市场上展现出广泛的应用潜力。