近日,数据空间研究中心在高效异构联邦学习领域取得了一项研究成果。该研究旨在应对K-异步联邦学习中可能面对的非独立同分布数据(Non-IID data)以及陈旧梯度所带来的挑战。研究团队受到反刍动物的启发,提出一种基于“知识反刍”策略,通过对已有知识的再次“咀嚼”与理解,从而进行联邦环境中的客户端效用的评估。研究团队通过与奥胡斯大学的研究者们合作开展研究,经过长时间的探索与实验,所取得的研究成果以论文形式发表于IEEE International Conference on Multimedia & Expo(ICME) 2025。
论文地址:https://arxiv.org/pdf/2312.10425
研究背景
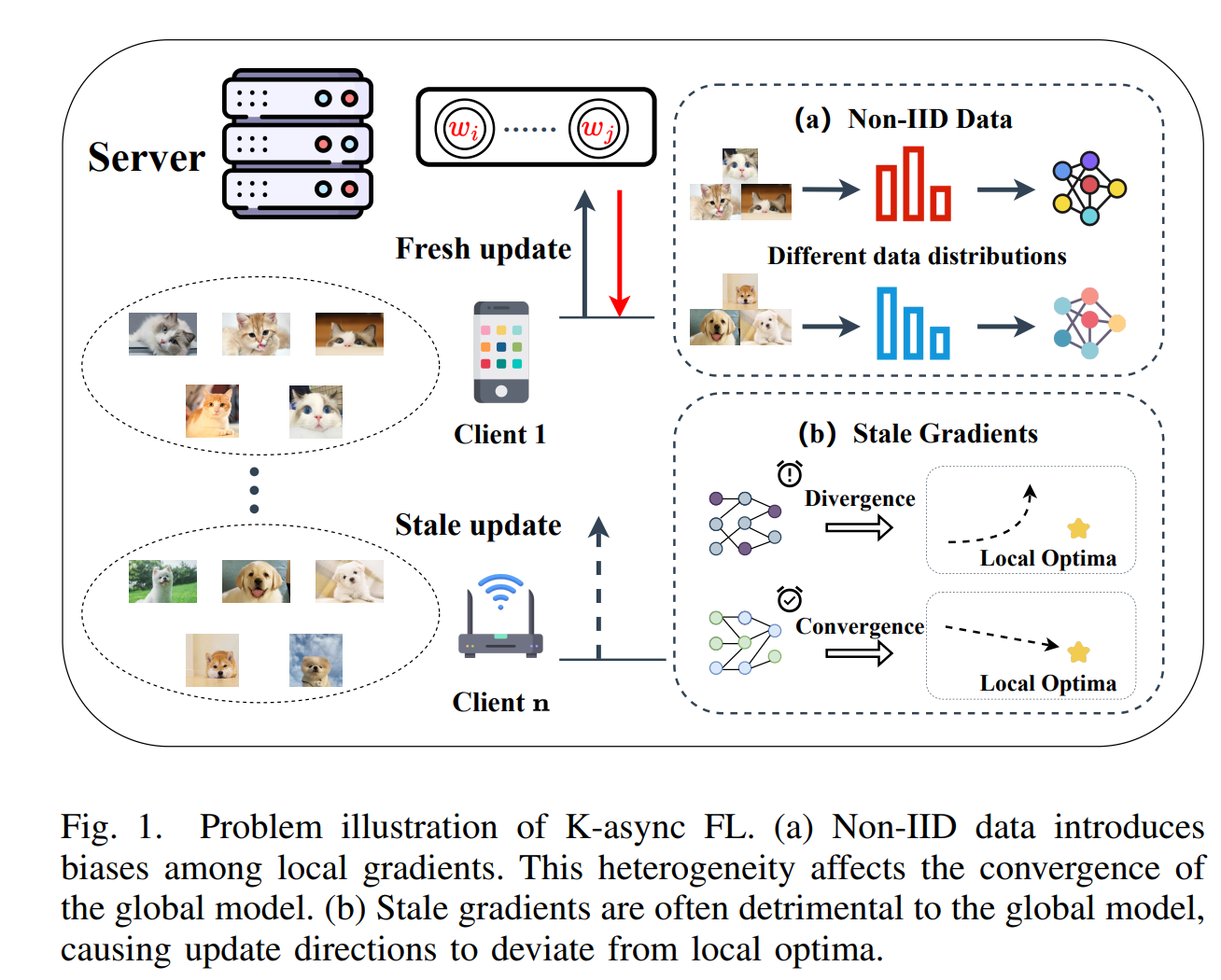
联邦学习(FL)作为一种分布式机器学习范式,近年来因其能够保护终端用户数据的隐私而受到广泛关注。在经典的 FL 工作流程中,每个客户端使用其私有数据来训练本地模型,然后将梯度上传到中央服务器。中央服务器将收集到的局部梯度聚合为全局梯度以更新全局模型,然后将其发送回客户端进行后续训练。整个过程不会泄露原始数据。因此,FL 有效地保护了数据隐私,并在医疗保健、自动驾驶和移动键盘预测等各个领域提供了独特的优势。一种著名的 FL 聚合算法是联邦平均 (FedAvg),其中服务器聚合来自选定的一组本地客户端的更新,并通过应用加权平均策略来计算全局模型。由于系统和设备之间的统计异质性,这种方法经常会遇到落后效应,这严重阻碍了训练进度。为此,研究人员引入了异步 FL (AFL),其中服务器不再等待所有客户端,但可以在收到单个局部梯度后立即更新全局模型。然而,AFL 可能会导致全局模型偏向快速客户端,频繁的数据传输可能会导致服务器崩溃。一些研究试图在同步和异步方法之间寻求一种折衷方案,其中 K-async FL 已显示出有希望的结果,特别是在高度异构的环境中。在 K-async FL 中,服务器在收到前 K 个局部梯度后立即启动聚合,而其余客户端继续训练。尽管 K-async FL 性能良好,但它仍然受到两个挑战的制约,如图 1 所示。一方面,非独立同分布 (Non-IID) 数据的存在对训练性能良好的全局模型构成了重大挑战。另一方面,陈旧的局部梯度的存在往往会影响全局梯度的效用,甚至导致发散。
研究方法
为了解决这一问题,研究人员提出了三种组件结合的方法,名为FedHist,它包括(1)梯度稳定性增强 Enhancement of Gradient Stability (EGS);(2)历史感知的梯度聚合History-Aware Aggregation (HAA);(3)智能范数放大Intelligent Norm Amplification (INA),框架如图2所示。
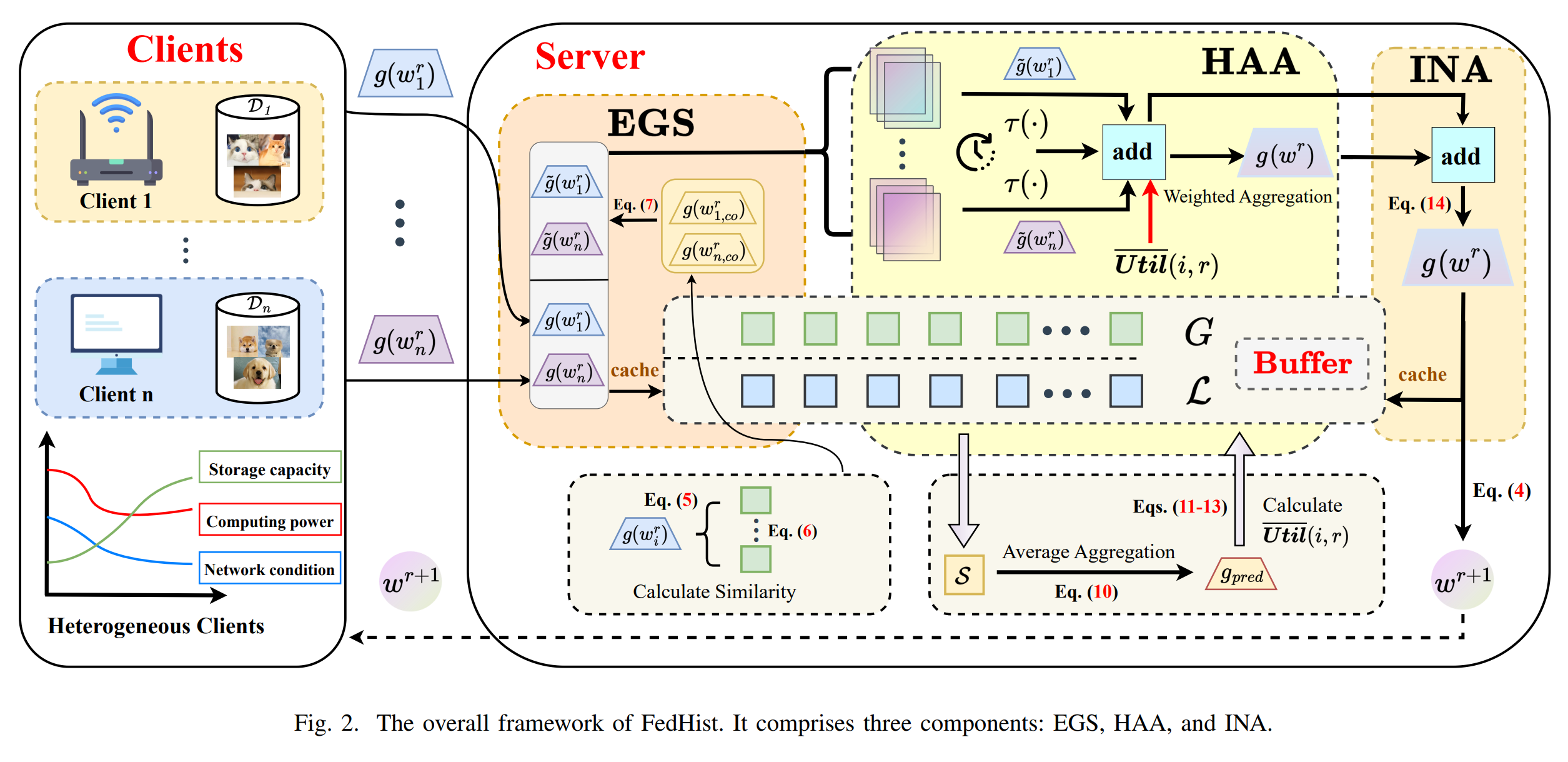
对于(1),团队提出利用历史全局梯度来增强新一轮中本地梯度的稳定性;对于(2),利用周期性的反刍,模型将会回顾若干轮次之前的参与聚合的客户端的表现,首先通过服务器端的缓冲区来寻找Relatively fresh updates,随后进行Predicted unbiased gradients,并根据预测结果进行Client utility evaluation。通过比较实际使用的全局梯度(实际使用的)与理想的全局梯度(一定轮次后反刍得到的),参与聚合的客户端的能力得到了评估,随后被用于后续聚合的赋予权重的依据。对于(3),团队观察到直接聚合梯度可能会导致L2范数的缩减,这源于各个梯度之间方向的不一致。因此团队提出了一种简单但有效的梯度放大策略以加速收敛。
实验结果
在公共数据集上进行的大量实验表明,团队提出的FedHist 的表现优于最先进的方法,并有效地促进了训练过程的公平性。
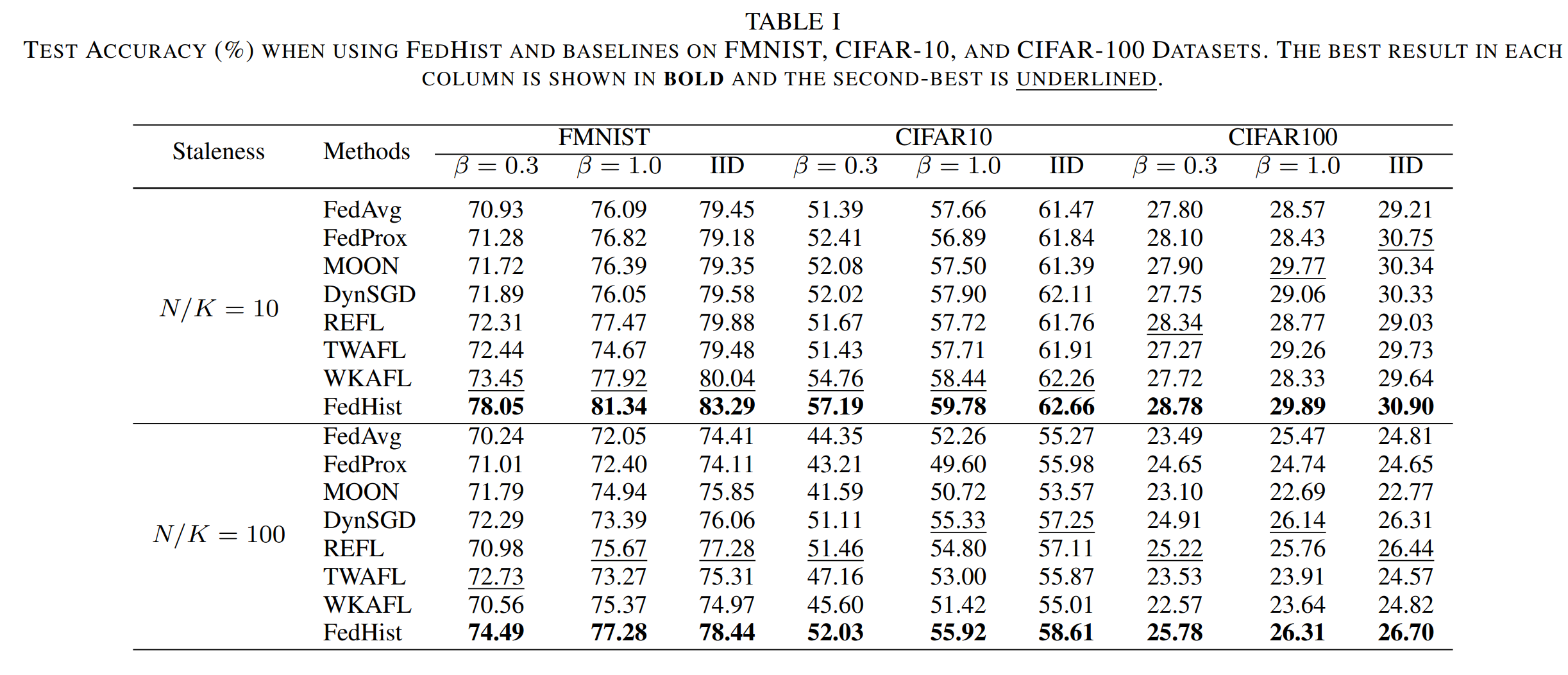
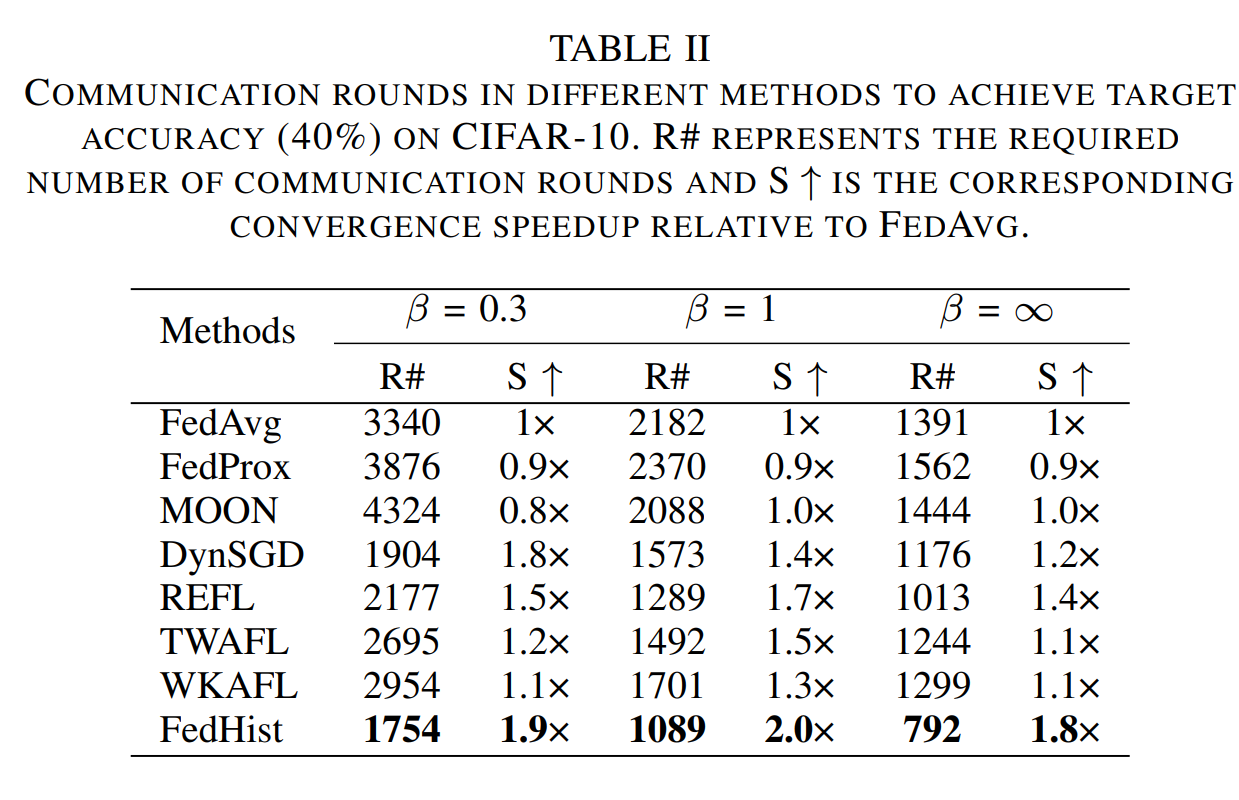
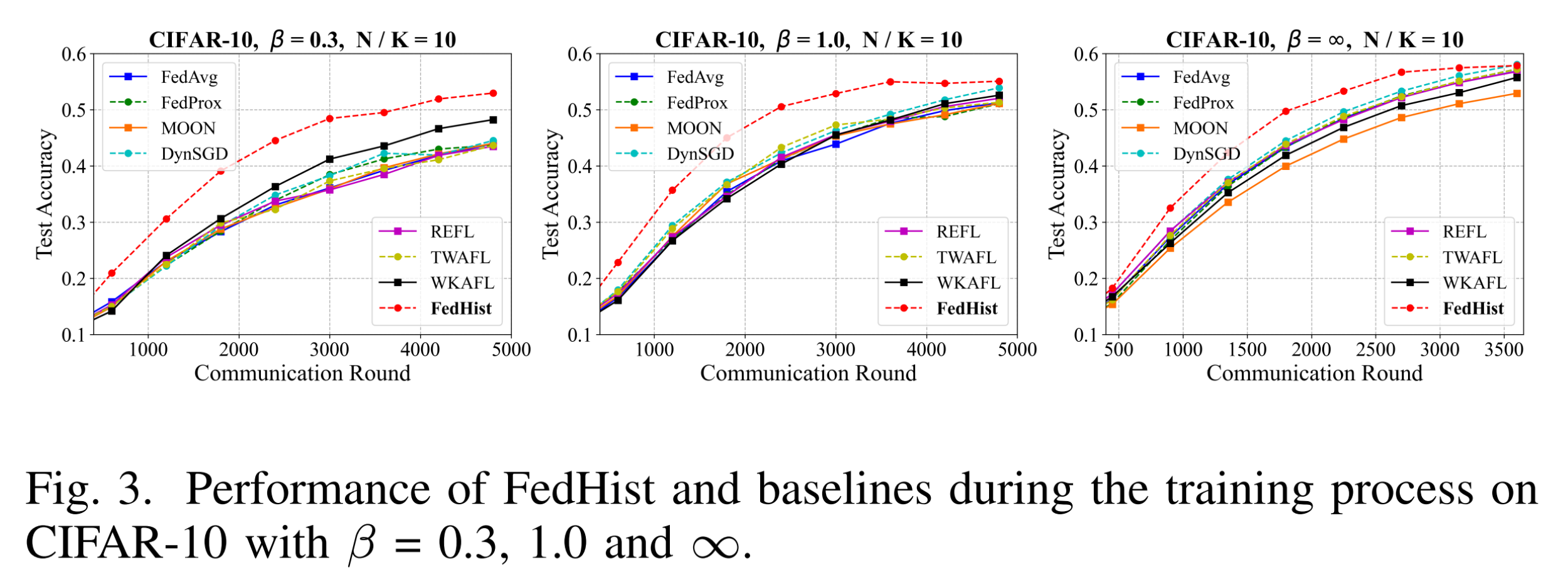
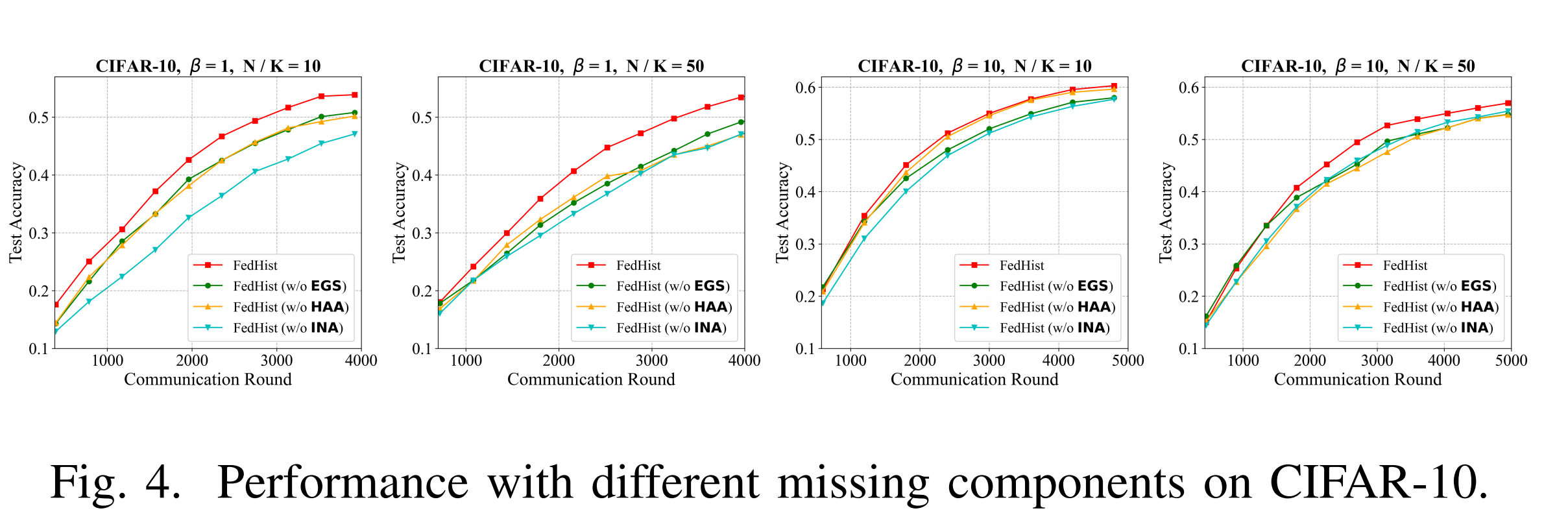
研究团队主要在对比实验(表1),通信轮次实验(表2),对比收敛曲线(图3),消融收敛曲线(图4)和公平性实验(图5)中进行了充分的验证,结果如下:
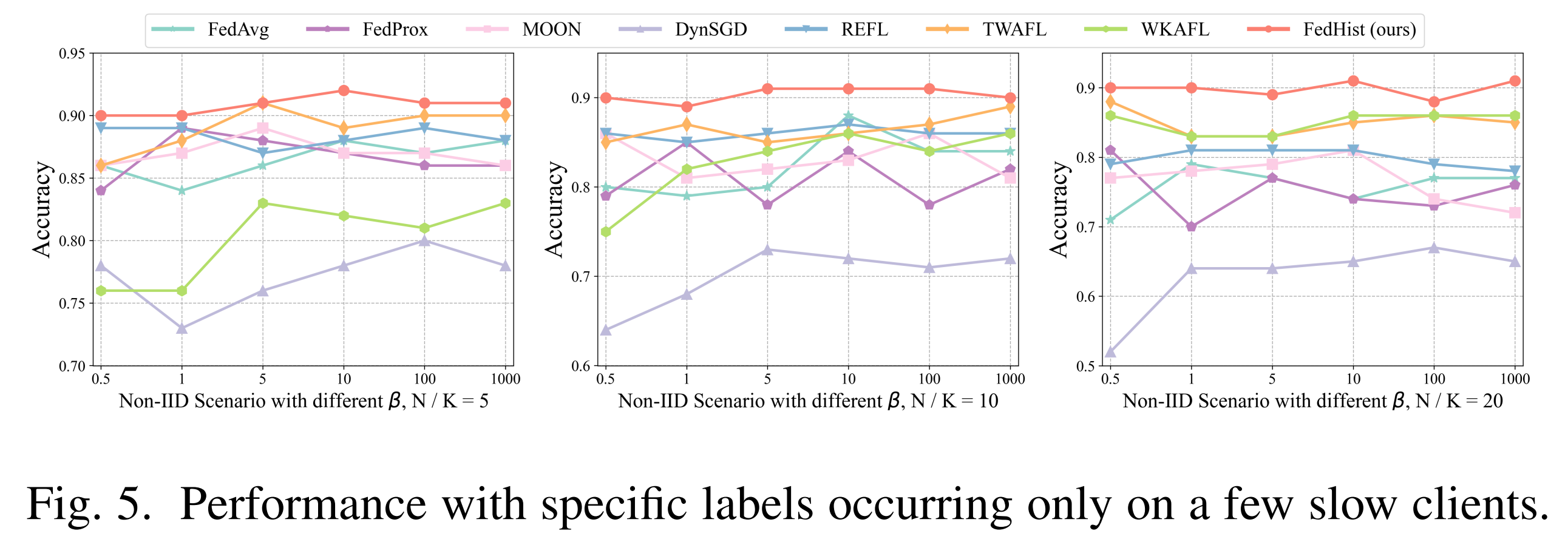
研究结论
在这项研究中,团队提出了一种新颖的 AFL 方法 (FedHist),该方法重现历史梯度的知识并反映客户端的效用。FedHist 首先通过细粒度交叉聚合增强了局部梯度的稳定性。它以多维方式分配聚合权重,并通过调整聚合梯度的 L2 范数实现快速稳定的收敛。研究团队在公共数据集上进行了广泛的实验并验证了其有效性。