数据空间研究中心近日在多智能体强化学习的安全领域发表了一项重要研究成果。
协作多智能体强化学习的策略容易受到针对状态和动作的对抗性扰动的影响。以往的对抗攻击工作主要集中在有限的攻击次数的情况下直接通过白盒攻击的方式对受害者智能体的状态或者动作进行扰动从而影响受害者智能体的策略,但在实际环境中我们是很难直接获得受害者智能体的完全访问权限的。

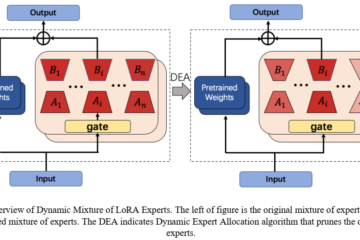
图表1. CuDA2框架。如图中绿色方框所示,我们需要明确叛徒攻击的目标:提前训练并保存一个受害者智能体的模型。其次,如图中灰色方框所示,我们还需要在叛徒采取随机动作的策略中预训练RND模块,这样可以减少因为叛徒采取的随机动作而导致的受害者智能体状态变化产生的预测误差。最后,在训练叛徒之前,加载受害者智能体模型。在训练过程中,使用预训练的RND模块作为势函数通过动态基于势能的奖励塑造的方式给予叛徒额外奖励。
为了实现更切合实际的对抗攻击,如图表1所示,我们首先引入了给受害者智能体注入叛徒智能体的攻击方式。为了解决这个问题,我们将问题建模为Traitor MDP (TMDP),其中叛徒是无法直接对受害者智能体进行攻击的,只能通过碰撞的方式影响受害者智能体的阵型或者站位。在TMDP中,叛徒智能体用的MARL算法与受害者智能体是一样的,叛徒的奖励函数可以简单设置成负的受害者智能体的奖励。但这样训练叛徒效率低,叛徒很难将自己的行为与受害者的奖励直接关联起来。鉴于此,我们提出了好奇心驱动的对抗攻击(CuDA2)框架,可以对指定的受害者智能体策略进行更高效更侵略的攻击,同时还能保证叛徒的最优策略不变性。具体来说,我们设置了一个经过预训练的RND模块,RND产生的额外奖励会鼓励叛徒通过自己的行为探索受害者智能体未曾见过的状态,最优策略不变性的证明在论文中有详细论述。

图表2. CuDA2与其他基线方法在星际争霸Ⅱ中游戏开始前后的行为对比。(a)叛徒保持原地不动。(b)叛徒会采取随机动作。(c)叛徒用和受害者智能体一样的算法进行训练,其奖励函数为负的受害者智能体奖励。(d)叛徒会接收CuDA2框架给予的额外奖励,叛徒会通过左右微小的移动来影响受害者智能体的观测和位置从而攻击他们的策略。

图表3. 引入一个叛徒的情况下CuDA2与其他基线的对比。(a)和(b)反映的是6个友军对6个敌军的场景中引入一个叛徒的胜率和友军阵亡数随训练时间的曲线图。(c)和(d)是8个友军对8个敌军的场景引入一个叛徒的曲线图。
如图表2和图表3所示,我们对来自SMAC的多个场景的广泛实验表明, CuDA2方法与其他基线相比能通过碰撞以及无规律的移动干扰受害者智能体的观测和位置,从而影响受害者智能体的策略使其做出错误的决策,最终导致更多的友军阵亡数,展现出更强的对抗攻击能力。同时在论文中,我们还做了不同数量的叛徒的实验,消融实验,以及使用了热图来展示受害者智能体与叛徒的活动范围。论文的链接如下:https://arxiv.org/pdf/2406.17425
陈振同学对目前强化学习多智能体领域的对抗攻击方法进行了充分调研,经过长时间的探索与实验,上述所取得的研究成果以论文形式于2024年10月21日被IEEE Transactions on Games 期刊接收,论文题为“CuDA2: An Approach for Incorporating Traitor Agents into Cooperative Multi-Agent Systems”。 该研究受到安徽省重点研发计划(2022YFB3105405和2021YFC3300502)和国家重点研发计划(202423110050033)的资助。