研究中心近日在联邦推荐系统领域发表了一项重要研究成果。
在当今数字化时代,随着个性化服务需求的日益增加,联邦推荐系统作为一种新兴的推荐技术,正逐渐受到关注。然而,在联邦环境的隐私约束下,这类系统能否实现群体公平性仍然是一个尚待深入研究的问题。经过长达一年多的研究,团队针对性别公平性这一典型议题取得了阶段性的进展,在数据挖掘顶级会议The 18th ACM International Conference on Web Search and Data Mining(WSDM 2025)发表一篇题为“Privacy-Preserving Orthogonal Aggregation for Guaranteeing Gender Fairness in Federated Recommendation”的论文。
首先,团队发现联邦推荐系统中性别间存在表现差异、数据失衡和偏好差异等现象:如下图所示,图(a)显示FedMF在ML-1M数据集上为男性用户提供的推荐比女性用户更好;图(b)显示数据集中每种性别的用户数量和交互记录存在显著差异;图(c)显示每种性别的前K个最喜爱物品的偏好差异高达50%。
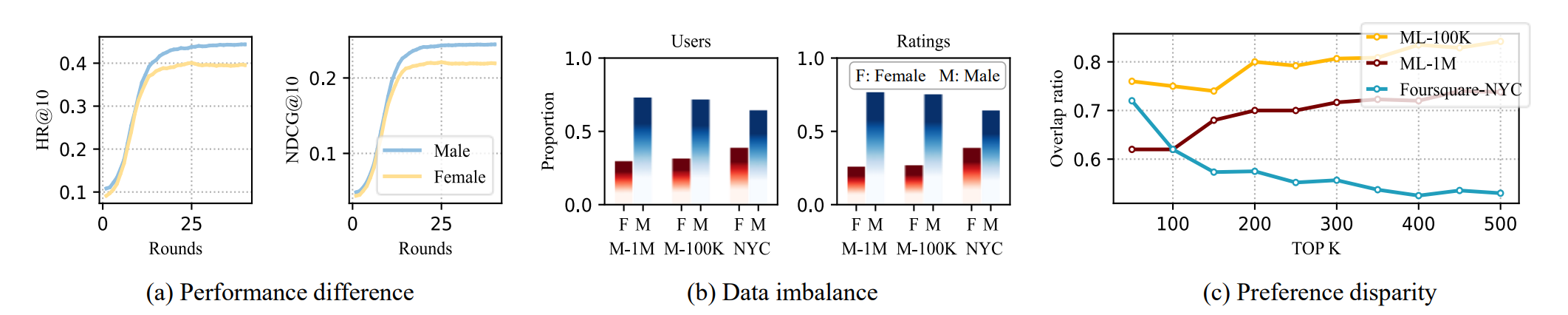
图1 联邦推荐系统中性别差异的三个表现
经过调研发现,现有的解决联邦推荐系统中公平的方法仅关注表现差异,仅仅通过调整优势群体和劣势群体的学习速度来寻求公平,例如F2MF指出:“The low-performance group needs to learn faster and the high-performance group needs to learn slower in order to produce a better group level fairness”。这种片面的公平约束反而对模型训练产生了负面影响。
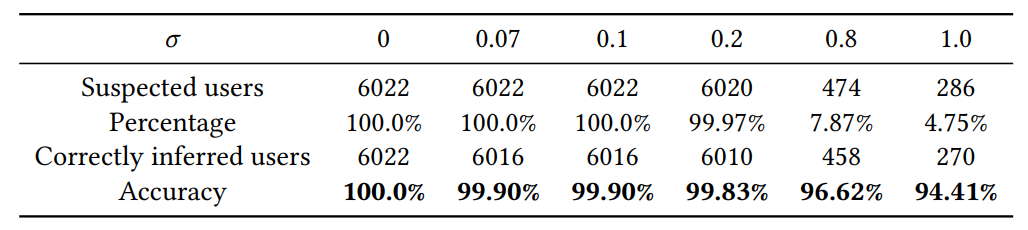
此外,团队的分析表明,现有基于噪声的方法在保护敏感属性方面存在隐私泄露风险。以一个简单的例子来说,代表男性的属性值为1,代表女性的属性值为0,现有的方法通过添加标准差为σ高斯噪声来保护用户的属性值从而保护用户的性别隐私。然而,由于高斯分布3σ准则的存在,如果一个属性值大于3σ,那么我们有大于99.73%的信心来推断该值代表的用户性别为男性。下表展示了该方法可以推断出性别的用户比例(Percentage)以及对这些用户进行攻击的成功率(Accuracy)。
表1 不同噪声下推断用户性别攻击的成功率
基于以上发现,团队识别出联合聚合阶段是导致性别不公的关键环节,这个阶段中少数群体的偏好往往被主导群体的偏好所淹没,例如,女性用户数量较少(数据不平衡)导致男性相关信息在聚合参数中占主导地位。因此,在聚合阶段防止群体间干扰可以提高群体公平性,尤其是对少数群体而言。为了解决这个问题,团队提出了一种新颖的隐私保护正交聚合方法(PPOA),该方法旨在避免多数群体对少数群体的压制,并有效保持不同群体的独特偏好,从而实现更好的群体公平性。具体地来说,团队设计了一个函数对(F,F’),F可以将男女用户的模型更新分别映射到相互正交的空间中,服务器对这个空间中的模型更新进行联邦聚合,用户可以使用F’将聚合结果映射到原有空间中,映射的结果中仅包含该用户所属的群体的模型聚合结果(如图2所示)。这样可以将本群体的模型更新赋予更大的权重,从而使得本群体的特征不会在模型聚合过程中被淹没。
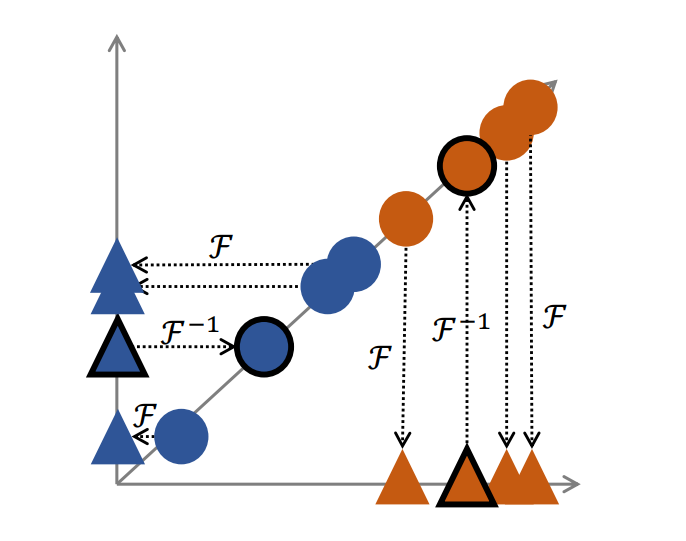
图2 正交聚合示意图。红色代表女性,蓝色代表男性。圆圈表示低维(原始)空间中的物品嵌入,三角形表示高维空间中的物品嵌入。带有黑色轮廓的元素表示聚合结果。
在对三个真实世界数据集的实验结果显示,PPOA在提高推荐效果方面表现优异:为女性和男性的推荐效果分别带来了最大8.25%和6.36%的提升,为总体用户带来了最大7.30%的提升。大多数情况下,PPOA还实现了最佳的公平性。团队使用t-SNE可视化方法来展示在三个数据集中使用PPOA训练后的男女各自的物品嵌入。如下图所示,蓝色和红色部分分别代表男性和女性,两部分往往表现出形状相似,我们认为这体现了群体之间的一些共同特征,而它们在空间分布上的差异是群体差异的表现,这与图1 (c)中体现的性别偏好差异是相对应的。
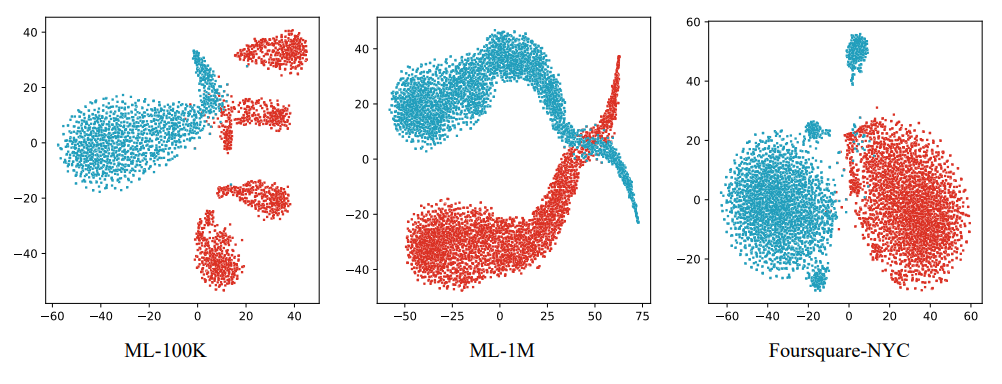
图3 三个数据集上男性和女性item-embedding的t-SNE可视化。蓝色表示男性,红色表示女性
此项研究不仅为联邦推荐系统的性别公平提供了新的视角,也为公平性、隐私性与性能提升之间的平衡开辟了新路径。此外,PPOA的可扩展性也为其他敏感属性的公平性研究提供了新的方向。未来,研究团队将继续探讨PPOA在不同数据场景下如何应对数据稀缺和极端不平衡带来的挑战。