研究中心提出大模型知识应用新框架,为提升大模型在知识密集任务上的性能提供新思路。
近日,由中国科学技术大学、复旦大学和新加坡管理大学等多所高校及科研机构合作完成的研究成果,以论文《A+B: A General Generator-Reader Framework for Optimizing LLMs to Unleash Synergy Potential》形式发表于The 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024)。该研究提出了一种全新的“A+B”生成器-阅读器框架,旨在优化大规模语言模型的协同潜力,提升其在知识密集型任务中的性能和安全性。
大规模语言模型在自然语言处理任务中取得了显著进展。然而,由于缺乏领域特定或最新知识,其在真实应用场景中存在显著局限。为弥补外部知识的缺乏,现有方法如基于检索增强生成的模型受到关注。RAG虽然提供了有潜力的解决方案,但在实际应用中检索器的性能逐渐成为了瓶颈:1)检索准确率低,2)query信息不全以来多跳推理,3)大模型易受噪音影响,致使应用存在准确率-召回率权衡。之前的研究者发现大模型本身可以作为知识库,并提出“先生成后阅读”的替代策略,但无法吸收外部知识,并且性能表现有限。

图1:chat版本的校准能力收到了损伤(图源OpenAI)
为了解决这个问题,研究团队首先发现到大模型的不同版本,即base版本和chat版本存在性能差异。根据OpenAI的技术报告,其发现经过对齐训练的chat版本在校准能力上存在显著下降。团队因此假设对齐微调会造成模型的知识性相关能力,如记忆能力,出现损伤。研究团队构建了两个记忆能力评估数据集,quote和poem,如图2所示,评估发现,无论模型的参数级别和结构版本,大模型的base版本在记忆能力上的表现都显著高于chat版本。


图2:base版本在记忆能力上的表现显著高于chat版本
基于此,团队提出了一种通用“A+B”框架,通过将生成器和阅读器分离为独立模块,分别由基础型模型(base)和对齐型模型(chat)担任。生成器负责生成与输入问题相关的上下文,强调知识记忆和准确性;阅读器负责解读生成内容并生成最终回答,侧重认知推理与用户偏好对齐。通过将阅读与生成在功能上解耦,“A+B”可以实现更相关、更全面、更准确、更安全,并且更灵活的知识型应用。
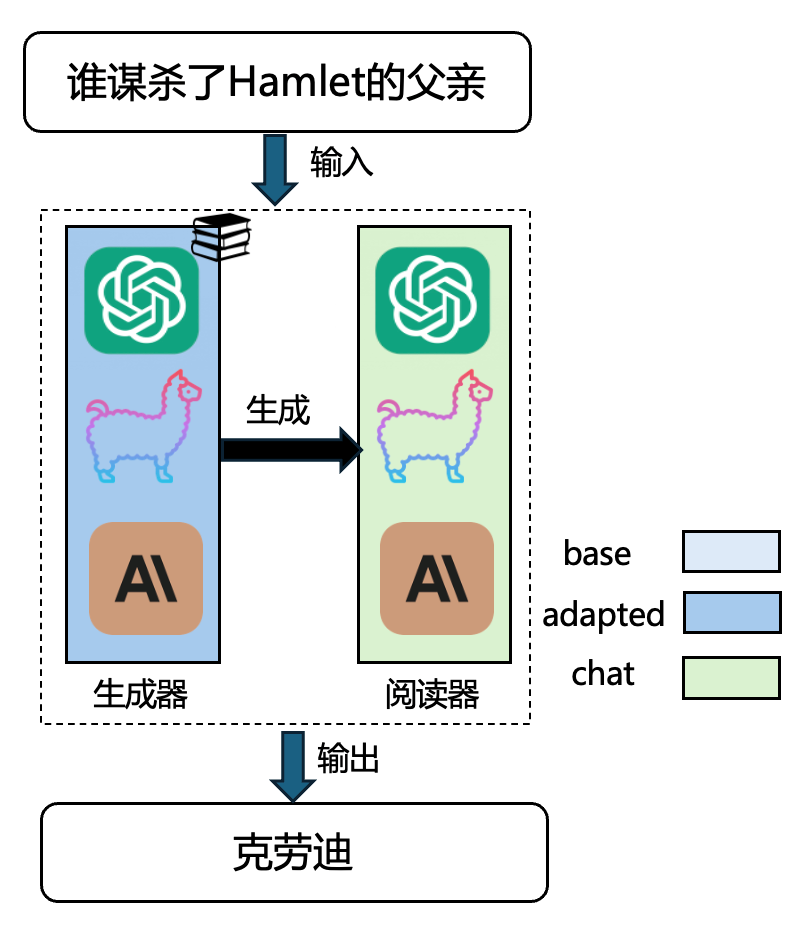
图3:A+B生成器-阅读器架构
研究团队在四个著名的知识应用数据集:Natural Question,Trivial QA,Web QA和Hotpot上进行了实验。如图4所示,实验结果说明:1)“A+B”的框架显著好于单独使用阅读器的结构,证明了“A+B”框架整体的有效性;2)使用base版本作为生成器时显著好于使用chat版本作为生成器时的性能,进一步验证了所提方法的有效性;3)实验还发现对“A+B”整体性能影响更大的是生成器的性能,这为未来实现高效的知识利用提供了更经济的参数扩大思路。
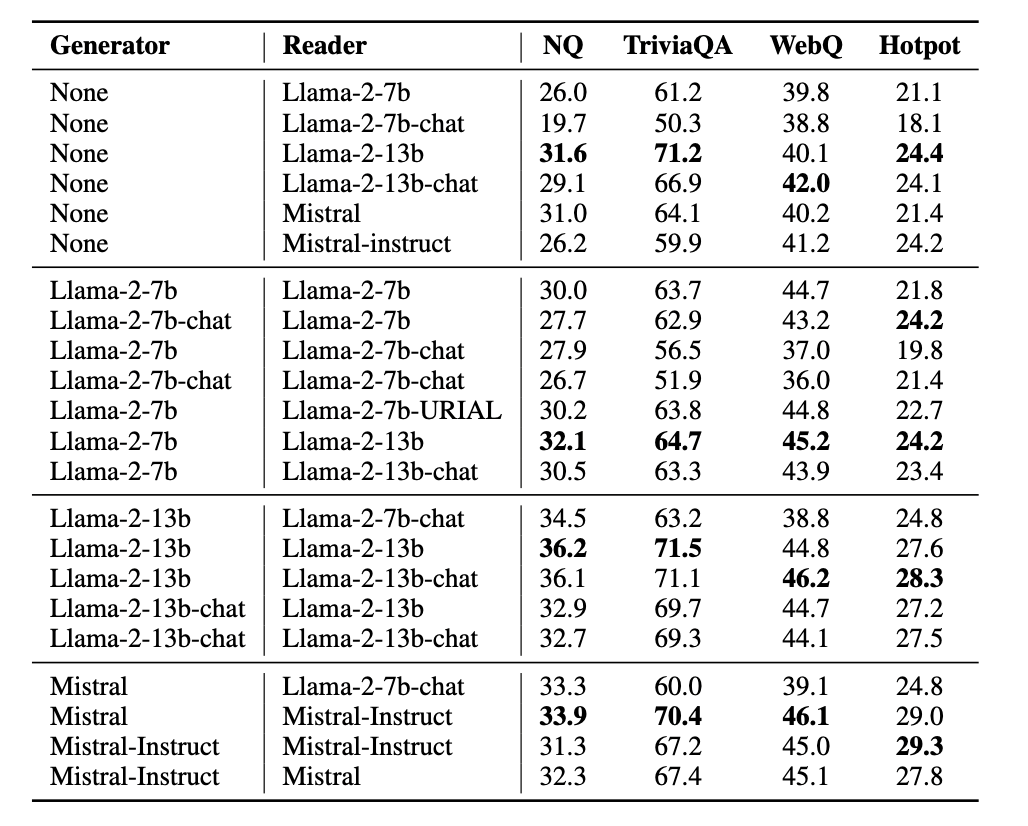
图4:A+B框架在多个数据集上的实验结果
除此之外,在对大模型的对齐能力进行分析时,发现无论是直接使用base版本,还是使用经过精心设计的ICL来对齐的URIAL类方法,始终距离chat版本存在较大差距。因此,chat版本是更安全的阅读器,并且是十分必要的。
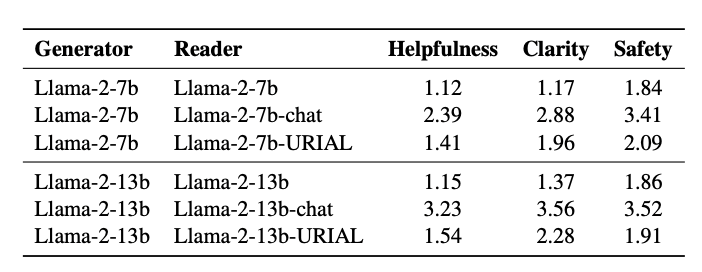
图5:A+B框架在对齐性能上的比较
进一步的,团队考虑到大模型利用新知识的场景,设计了一个基于连续学习的适应性方法,将新知识通过连续预训练注入到生成器的参数中,从而可以生成面向新知识的参考文本,实现新知识利用能力。在Narrative QA上的两个场景中测试,发现“A+B”的方法甚至超越了传统的基于RAG的方案,证明了“A+B”架构替换Retriever的潜力。
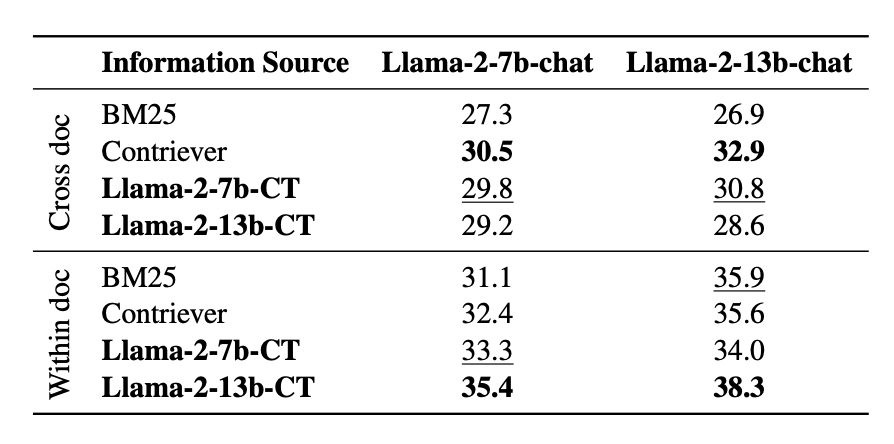
图6:“A+B”在新知识利用场景的表现
研究团队对文章的贡献总结如下:
- 通过前置实验发现base模型相比于chat模型具有更好的记忆能力;
- 提出“A+B”:一个通用的生成器-阅读器架构;
- 实验证明“A+B”的组合好于任意单个模型的性能;
- 在“A+B”中,base模型更适合做生成器,chat模型更适合做阅读器;
- “A+B”可以应用在需要新知识的扩展场景中,实质上提供了一种使用LLM来替代检索器的方案,为当前RAG系统的检索调优提供另一种视角。
该研究首次揭示了基础型模型和对齐型模型在生成与阅读任务中的协同潜力,为优化大模型在实际知识密集型任务中的性能提供了新思路。同时,通过扩展“A+B”框架的适用场景,展示了其在整合外部知识及提升模型安全性和实用性方面的显著优势。未来,研究团队计划探索更大规模的知识集成与更复杂任务场景下的框架表现,进一步推动其应用于学术研究与产业实践。
该研究获得了国家重点研发计划等项目资助,充分体现了多方协作与跨领域创新的科研精神。