数据空间研究中心于近日在空间智能——3D编辑领域发表了一项重要的研究成果。
项目主页:https://3d-goi.github.io/
论文地址:https://arxiv.org/abs/2311.12050
生成式3D模型的迅猛发展引起了人们广泛的关注,尤其是在自动化3D对象和场景的生成及编辑方面。然而,目前大多数方法主要集中在单一对象上,如3D人脸生成和人脸新视角的合成。针对多对象3D场景的生成手段尚不成熟,这些场景的编辑技术更是未被充分探索。在我们所处的真实三维世界中,开发有效的真实3D场景编辑方法成为了3D编辑领域亟待解决的核心问题。

李浩冉同学对3D场景编辑的方法进行了调研,并与合肥工业大学以及奥胡斯大学的研究者们合作开展研究。经过长时间的探索与实验,所取得的研究成果以论文形式发表于计算机视觉三大顶级会议之一的ECCV2024(The 18th European Conference on Computer Vision),论文题为“3D-GOI: 3D GAN Omni-Inversion for Multifaceted and Multi-object Editing”。3D-GOI框架支持对多对象图像进行仿射编辑,包括缩放、平移、旋转、外观和背景调整,如上图所示。
技术方案
3D-GOI使用3D GAN(GIRAFFE[1])反演实现对输入复杂场景图片的解耦合,得到基于3D GAN生成多个codes。然后通过改变codes值,实现多元化的编辑。
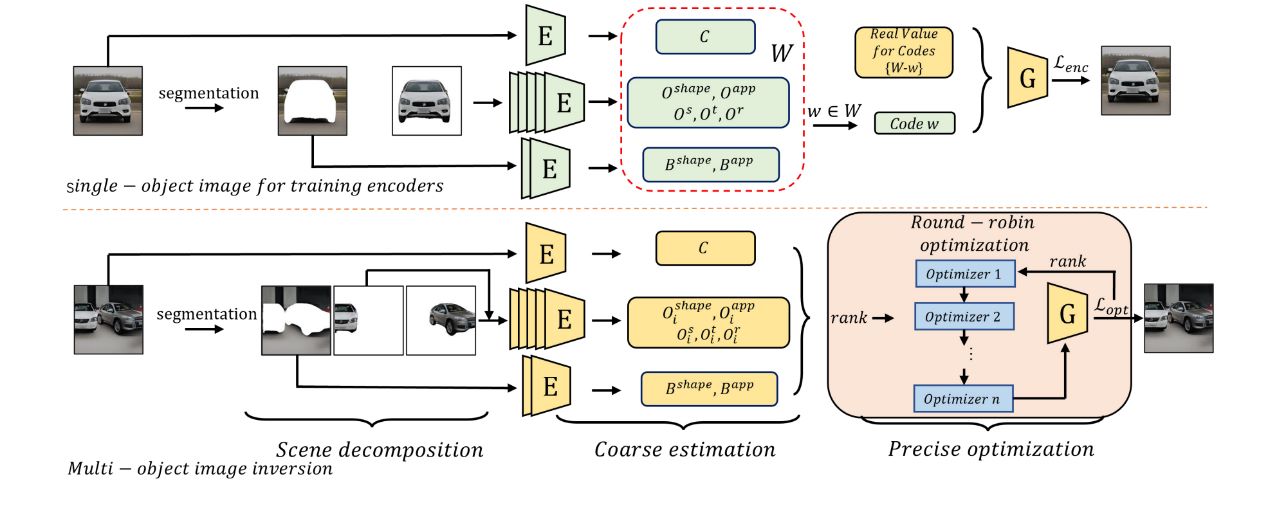
如上图所示3D-GOI主要由三个阶段构成。第一个阶段通过分割的手段,分离各个物体以及背景。这源于组成物体的codes作用于物体本身,减少其他物体对该物体codes的影响。同时我们可以在单个物体的场景图片中训练,在多物体场景中推理,进而减少训练的难度。
第二个阶段,我们根据GIRAFFE的神经渲染模块,反向构造神经反演编码器如下图所示,目的是粗略估计属于当前物体或者背景的codes。在这一过程中,我们为每一个code设计一个编码器,让其专注于特定属性的预测。我们在单物体场景上通过反向传播重建损失训练每个编码器,在推理阶段,我们冻结编码的参数,输出多个粗略的codes。
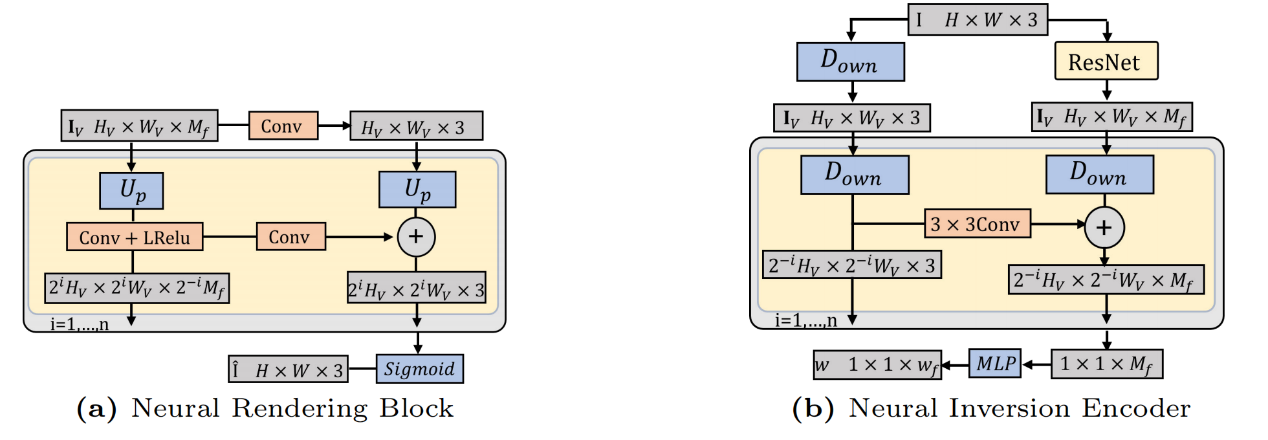
在第三阶段,我们将粗略估计的codes通过算法优化得到其精确值,我们发现,将所有codes全部放入一个优化器优化容易陷入局部最小。所以我们提出循环优化算法,如下算法所示。我们发现优先优化对图片生成中改变像素值大的codes,如背景颜色code,背景形状code,对整体的优化更好。

得到可以精确重建图像的codes后,我们可以任意改变不同物体不同属性的code进行编辑,实现多元多物体的3D编辑。
实验评估
单对象与多对象编辑 下图分别展示了在 G-CompCars 数据集上的单物体和多物体编辑结果。编码器生成的粗略重建图像在简单场景中已能达到较高精度,但对于复杂的汽车图像,需要通过循环优化进一步提升精度。实验结果表明,本文的方法在编辑对象的外观、形状、背景和相机姿态等方面表现优异。


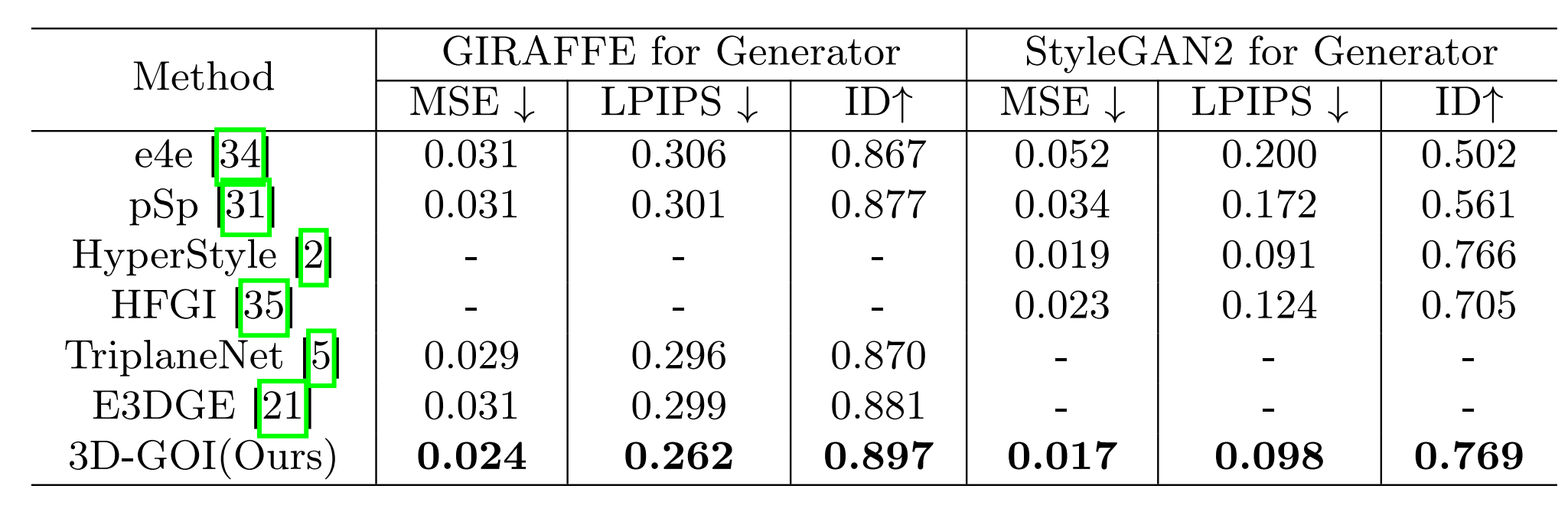
与基准方法的比较 作者将3D-GOI与现有的2D和3D GAN逆向方法进行了定量和定性比较,包括 e4e、pSp、TriplaneNet 和 E3DGE 等。如下表所示,分别在GIRAFFE和StyleGAN2生成器上的实验表明,本文的方法在重建质量、感知相似度和身份保持上均优于现有方法。
消融实验 为了验证每个模块对整体性能的贡献,作者对神经反转编码器和循环优化算法进行了消融实验。结果如下表的左侧显示,NIB(神经反转模块)和MLP(多层感知机)结构显著提升了代码预测的准确性。下表的右侧可见3D-GOI的轮询优化算法在所有指标上均优于固定顺序的算法,表明其在优化复杂场景中的优势。

[1] Niemeyer, M., Geiger, A.: Giraffe: Representing scenes as compositional generative neural feature fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11453–11464 (2021)