近日,数据空间研究中心在人工智能视频检测领域取得了重要研究成果。该研究旨在应对日益逼真的AI生成视频所带来的潜在安全风险,提出了一种基于帧一致性的AI生成视频检测模型,并构建了首个开源的AI生成视频检测数据集。通过与北京大学、浙江大学以及奥胡斯大学的研究者们合作开展,研究经过长时间的探索与实验,所取得的研究成果以论文形式发表于IEEE International Conference on Multimedia & Expo(ICME) 2025。
论文地址:https://arxiv.org/abs/2402.02085
研究背景
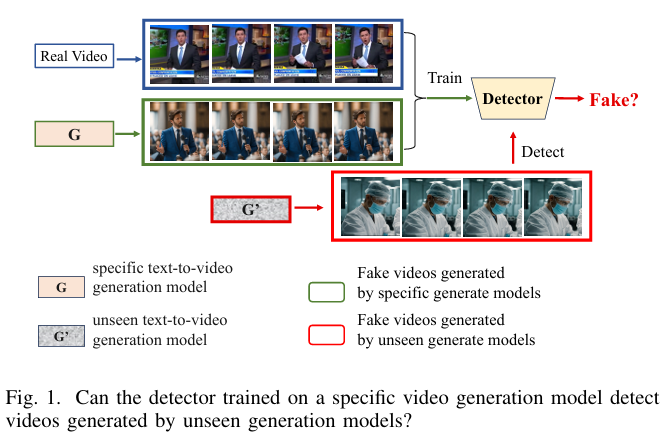
随着AI技术的飞速发展,AI生成视频的质量越来越高,甚至能够以假乱真,欺骗人类的眼睛。这种技术虽然在娱乐、教育等领域有着广泛的应用前景,但也带来了诸多安全隐患,如隐私侵犯、虚假信息传播、社交媒体信任危机等。因此,如何有效检测AI生成视频,成为了一个亟待解决的问题。然而,目前针对AI生成视频检测的研究相对较少。传统的检测方法主要依赖于时空神经网络(STNNs),这些网络虽然在视频理解等任务中表现出色,但在检测AI生成视频时,却存在明显的局限性。研究发现,这些网络往往过于依赖视频中的空间伪影,而忽视了更具普遍性和可泛化性的时序伪影,导致在面对未见过的视频生成模型时,检测性能大幅下降。

研究方法
为了解决这一问题,研究人员提出了两项创新性成果:一是构建了一个全面的AI生成视频检测数据集——Generated Video Forensics(GVF)数据集;二是开发了一种基于帧一致性的检测模型(DeCoF)。
l GVF数据集
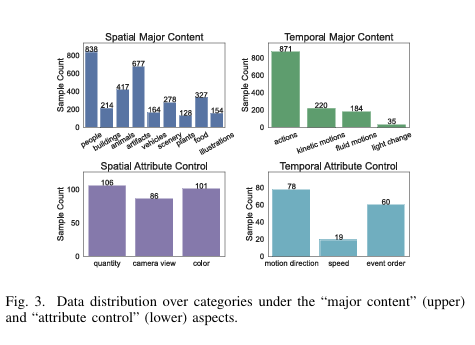
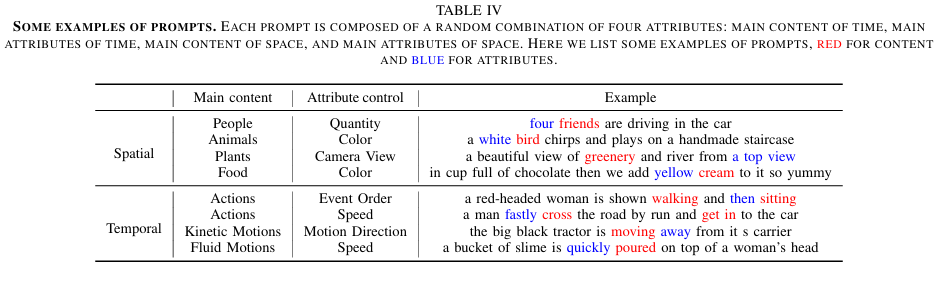
Generated V ideo Forensics(GVF)数据集是首个专门用于AI生成视频检测的数据集,涵盖了多种场景、行为和动作,通过将输入提示划分为独立的维度,实现了对不同生成模型的广泛覆盖。该数据集包含了964个真实视频与对应文本提示,以及由9种不同的文本到视频(T2V)生成模型生成的假视频,这些模型包括流行的商业模型如OpenAI的Sora、Google的Veo和快手的Kling等。通过精心设计的提示和真实视频选择,GVF数据集能够模拟现实世界中的多样化环境,为检测模型的训练和评估提供了丰富的素材。

l DeCoF检测模型
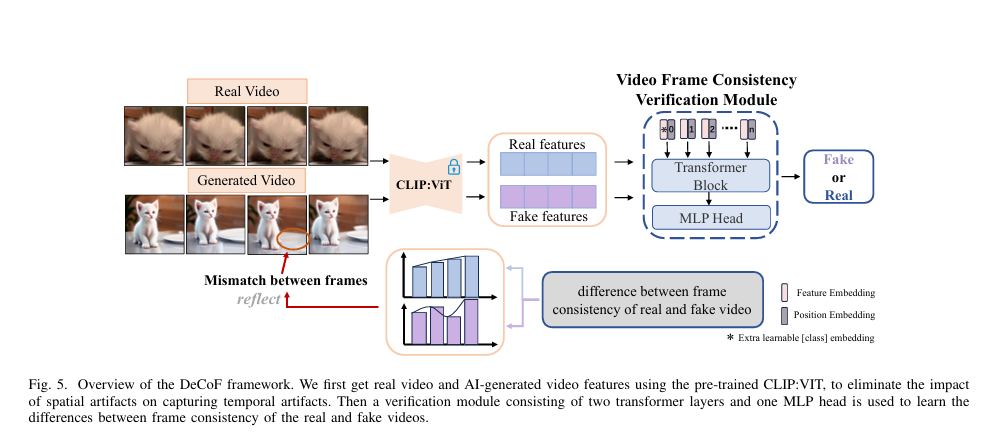
Detection model based on Concistency of Frame (DeCoF)模型的核心思想是通过分析视频帧之间的一致性来检测AI生成视频。该模型首先利用预训练的CLIP:ViT模型提取视频帧的特征,将视频帧映射到一个特征空间,在这个空间中,特征之间的距离与图像相似度成反比,且对空间伪影不敏感。这样,模型就可以专注于学习帧之间的时序伪影,而不是被空间伪影所干扰。然后,通过一个包含两层Transformer和一个MLP头的验证模块,模型能够有效地捕捉帧一致性之间的差异,从而判断视频的真实性。
实验结果
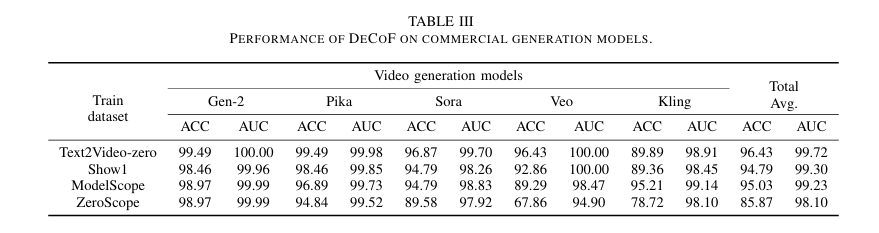
研究人员通过大量实验验证了DeCoF模型的有效性和泛化能力。实验结果表明,DeCoF在检测AI生成视频方面表现出色,尤其是在面对未见过的生成模型时,其准确率(ACC)和曲线下面积(AUC)指标均显著优于现有的检测方法。例如,在对Sora、Veo和Kling等商业模型生成的视频进行检测时,DeCoF的ACC和AUC指标均达到了90%以上,展现了强大的泛化能力。此外,DeCoF在跨数据集检测方面也表现出色,其在不同子数据集上的平均ACC和AUC指标均高于其他方法。
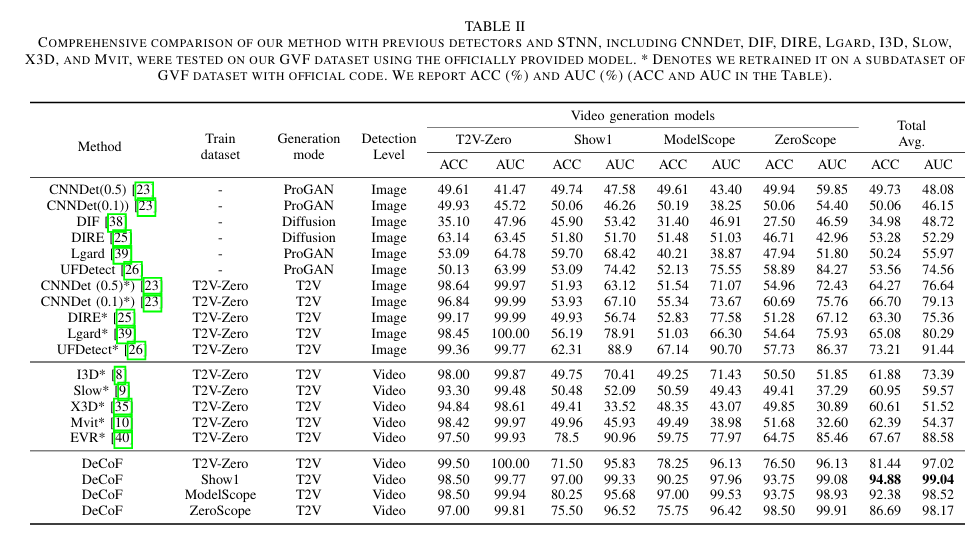
研究意义与未来展望
这项研究不仅为AI生成视频检测领域提供了首个开源数据集和一种有效的检测模型,而且对于应对AI技术带来的安全挑战具有重要的现实意义。随着AI生成视频技术的不断发展,其在虚假信息传播、隐私侵犯等方面的风险也在不断增加。DeCoF模型的出现,为检测和防范这些风险提供了一种有力的工具,有助于维护网络空间的安全和稳定。
未来,研究人员将继续优化DeCoF模型,提高其检测性能和泛化能力,同时探索更多类型的AI生成内容检测方法。此外,他们还将进一步完善GVF数据集,增加更多类型的视频和生成模型,以更好地支持相关研究的发展。